Index
- Guessing Game
- Common Programming Concepts
- Understanding Ownership
- Using Structs
- Enums and Pattern Matching
- Managing Growing Projects with Packages, Crates, and Modules
- Defining Modules to Control Scope and Privacy
- Paths for Referring to an Item in the Module Tree
- Bringing Paths into Scope with the use Keyword
- Separating Modules into Different Files
- Common Collections
- Error Handling
- Generic Types, Traits, and Lifetimes
- Writing Automated Tests
- Object Oriented Programming
- Adding dependancies
- Option Take
- RefCell
- mem
- Data Structure
- Recipe
- Semi colon
- Calling rust from python
- Default
- Crytocurrency With rust
- Function chaining
- Question Mark Operator
- Tests with println
- lib and bin
- Append vector to hash map
- Random Number
- uuid4
- uwrap and option
- Blockchain with Rust
- Near Protocol
- Actix-web
Linked List
Linked Lists:
To keep track of a bunch of items, there is a simple solution: with each entry in the list, store a pointer to the next entry. If there is no next item, store null/nil/None and so on, and keep a pointer to the first item. This is called a singly linked list, where each item is connected with a single link to the next:

In other words, its a queue (or LIFO—short for Last In First Out) structure.
struct Node {
value: i32,
next: Option<Node>
}
value: i32,
next: Option<Node>
}
For practical considerations, it needs a way to know where to start and the length of the list. Considering the planned append operation, a reference to the end (tail) would be useful too:
struct TransactionLog {
head: Option<Node>,
tail: Option<Node>,
pub length: u64
}
head: Option<Node>,
tail: Option<Node>,
pub length: u64
}
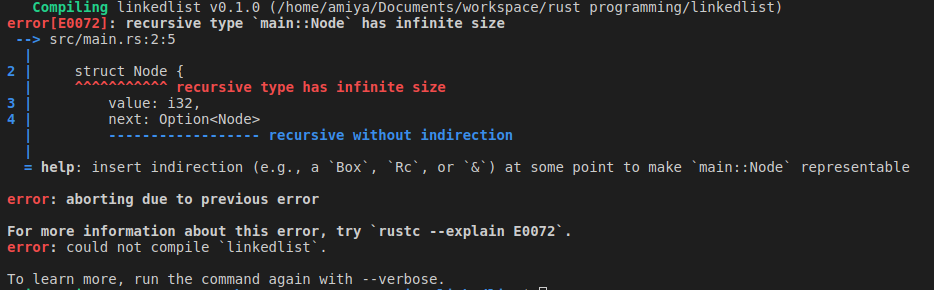
Unfortunately, it
doesn
't work
Because the compiler cannot be certain of the data structure's size
fn main() {
struct Node {
value: i32,
next: Option<Node>
}
}
struct Node {
value: i32,
next: Option<Node>
}
}
Reference types (such as Box, Rc, and so on) are a good fit, since they allocate space on the heap and therefore allow for larger lists. Here's an updated version:
use std::cell::RefCell;
use std::rc::Rc;
struct Node {
value: i32,
next: Option<Rc<RefCell<Node>>>,
}
struct TransactionLog {
head: Option<Rc<RefCell<Node>>>,
tail: Option<Rc<RefCell<Node>>>,
pub length: u64,
}
fn main() {}
use std::rc::Rc;
struct Node {
value: i32,
next: Option<Rc<RefCell<Node>>>,
}
struct TransactionLog {
head: Option<Rc<RefCell<Node>>>,
tail: Option<Rc<RefCell<Node>>>,
pub length: u64,
}
fn main() {}
#[derive(Clone)]
Differs from Copy in that Copy is implicit and extremely inexpensive, while Clone is always explicit and may or may not be expensive.
This trait can be used with #[derive] if all fields are Clone. The derived implementation of clone calls clone on each field.
use std::cell::RefCell;
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>; //Another good practice is to alias types, especially if there are a lot of generics in play
#[derive(Clone)]
struct Node {
value: i32,
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
fn main() {}
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>; //Another good practice is to alias types, especially if there are a lot of generics in play
#[derive(Clone)]
struct Node {
value: i32,
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
fn main() {}
use std::cell::RefCell;
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>;
#[derive(Clone)]
struct Node {
value: String, // 2. Change to string
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
impl Node {
// 1. A nice and short way of creating a new node
fn new(value: String) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node { // 3.Returns reference of node (Rc<RefCell<Node>>) with value = value, and next = None
value: value,
next: None,
}))
}
}
// 4. Implementation of transaction log
impl TransactionLog{
pub fn new_empty() -> TransactionLog{
TransactionLog {head: None, tail:None, length: 0}
}
}
fn main() {}
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>;
#[derive(Clone)]
struct Node {
value: String, // 2. Change to string
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
impl Node {
// 1. A nice and short way of creating a new node
fn new(value: String) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node { // 3.Returns reference of node (Rc<RefCell<Node>>) with value = value, and next = None
value: value,
next: None,
}))
}
}
// 4. Implementation of transaction log
impl TransactionLog{
pub fn new_empty() -> TransactionLog{
TransactionLog {head: None, tail:None, length: 0}
}
}
fn main() {}
Still, there is a lot missing. To recap, the transaction log has two requirements:
• Append entries at the end
• Remove entries from the front
Adding Entries
The transaction log can now be created and hold entries, but there is no way to add anything to the list. Typically, a list has the ability to add elements to either end—as long as there is a pointer to that end. If that was not the case, any operation would become computationally expensive, since every item has to be looked at to find its successor. With a pointer to the end (tail) of the list, this won't be the case for the append operation; however, to access a random index on the list, it would require some time to go through everything.
use std::cell::RefCell;
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>;
#[derive(Clone)]
struct Node {
value: String, // 2. Change to string
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
impl Node {
// 1. A nice and short way of creating a new node
fn new(value: String) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node {
// 3.Returns reference of node (Rc<RefCell<Node>>) with value = value, and next = None
value: value,
next: None,
}))
}
}
// 4. Implementation of transaction log
impl TransactionLog {
pub fn new_empty() -> TransactionLog {
TransactionLog {
head: None,
tail: None,
length: 0,
}
}
// 5. The append operation
pub fn append(&mut self, value: String) {
let new = Node::new(value);
// 6. `fn take` Takes the value out of the option, leaving a None in its place.
// Here the self is `TransactionLog` and `tail` is a `Option<Rc<RefCell<Node>>>` (SingleLink)
// First run, due to `new_empty` call `tail` is `None`
// Then `head` is set to `Some(new.clone())`
// Then outside match block `tail` is set to `Some(new)`
// In the second run, tail has `Option<Rc<RefCell<Node>>>` the old `Some(new)` and its not None
// It goes to the `Some(old)` block as where `Old` is the value returned, i.e. `Node`
// Set the Node's `next` to a new Node (Look in the diagram 1 Node-Next is linked to 2 Node)
match self.tail.take() {
// 7. Check the borrow_mut() example
Some(old) => {
old.borrow_mut().next = Some(new.clone());
println!("In Some");
}
None => {
self.head = Some(new.clone());
println!("In None")
}
};
self.length += 1;
self.tail = Some(new);
}
}
fn main() {
let mut tns = TransactionLog::new_empty();
tns.append("First".to_owned()); // In None
tns.append("Second".to_owned()); // In Some
}
use std::rc::Rc;
type SingleLink = Option<Rc<RefCell<Node>>>;
#[derive(Clone)]
struct Node {
value: String, // 2. Change to string
next: SingleLink,
}
#[derive(Clone)]
struct TransactionLog {
head: SingleLink,
tail: SingleLink,
pub length: u64,
}
impl Node {
// 1. A nice and short way of creating a new node
fn new(value: String) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node {
// 3.Returns reference of node (Rc<RefCell<Node>>) with value = value, and next = None
value: value,
next: None,
}))
}
}
// 4. Implementation of transaction log
impl TransactionLog {
pub fn new_empty() -> TransactionLog {
TransactionLog {
head: None,
tail: None,
length: 0,
}
}
// 5. The append operation
pub fn append(&mut self, value: String) {
let new = Node::new(value);
// 6. `fn take` Takes the value out of the option, leaving a None in its place.
// Here the self is `TransactionLog` and `tail` is a `Option<Rc<RefCell<Node>>>` (SingleLink)
// First run, due to `new_empty` call `tail` is `None`
// Then `head` is set to `Some(new.clone())`
// Then outside match block `tail` is set to `Some(new)`
// In the second run, tail has `Option<Rc<RefCell<Node>>>` the old `Some(new)` and its not None
// It goes to the `Some(old)` block as where `Old` is the value returned, i.e. `Node`
// Set the Node's `next` to a new Node (Look in the diagram 1 Node-Next is linked to 2 Node)
match self.tail.take() {
// 7. Check the borrow_mut() example
Some(old) => {
old.borrow_mut().next = Some(new.clone());
println!("In Some");
}
None => {
self.head = Some(new.clone());
println!("In None")
}
};
self.length += 1;
self.tail = Some(new);
}
}
fn main() {
let mut tns = TransactionLog::new_empty();
tns.append("First".to_owned()); // In None
tns.append("Second".to_owned()); // In Some
}